.avif)
📌 Key Takeaways
Service inconsistencies in Class A Multifamily portfolios arise from coordination gaps between systems—a challenge solvable by a unified service fabric.
- Operational Latency Compromises Service: When PMS, access control, and ticketing systems operate independently, events arrive at different times across platforms, creating delays that compound into missed service commitments and resident-facing inconsistencies that erode the premium experience.
- Orchestration Establishes Clarity: A Unified Resident Experience Platform clearly defines ownership and escalation paths through standardized assignments, eliminating the "I thought you were handling it" problem that causes work orders and notifications to slip through cracks.
- Leading Indicators Predict Service Lapses: Tracking first-response time, operational latency detection, and redundant-action prevention reveals coordination problems before they cascade into escalations, enabling weekly corrections instead of monthly post-mortems.
- Pilot Before Portfolio Rollout: A focused 90-day pilot at one or two properties with pre-defined success criteria (such as 95% move-in completion within 24 hours and fewer than 0.05 escalations per move-in) generates evidence for confident scaling without enterprise-wide risk.
- Integration Enables Orchestration: Reliable PMS and access control integrations must exist first—producing timestamped, dependable events—before orchestration can coordinate workflows and enforce playbooks across properties.
Coordination beats feature sprawl when systems work together through a control-tower model that secures the consistent hospitality residents expect.
Regional Operations Directors, IT/Systems Leaders, and Finance stakeholders in Class A Multifamily operations will find actionable metrics and implementation guidance here, preparing them for the detailed orchestration framework that follows.
Consider a Regional Operations Director reviewing last quarter's performance across a 15-property portfolio. The data reveals a troubling pattern: a significant portion of move-in service requests missed their commitments, escalations doubled at three properties, and the team spent an entire week reconciling why access credentials were provisioned in the PMS but never synced to the door systems. The Director knows every property uses quality tools—a robust PMS, modern access control, and a dedicated ticketing system. Yet somehow, residents still experience service gaps, and the operations team spends more time chasing handoffs than delivering the seamless, hospitality-grade experience that defines Class A luxury living.
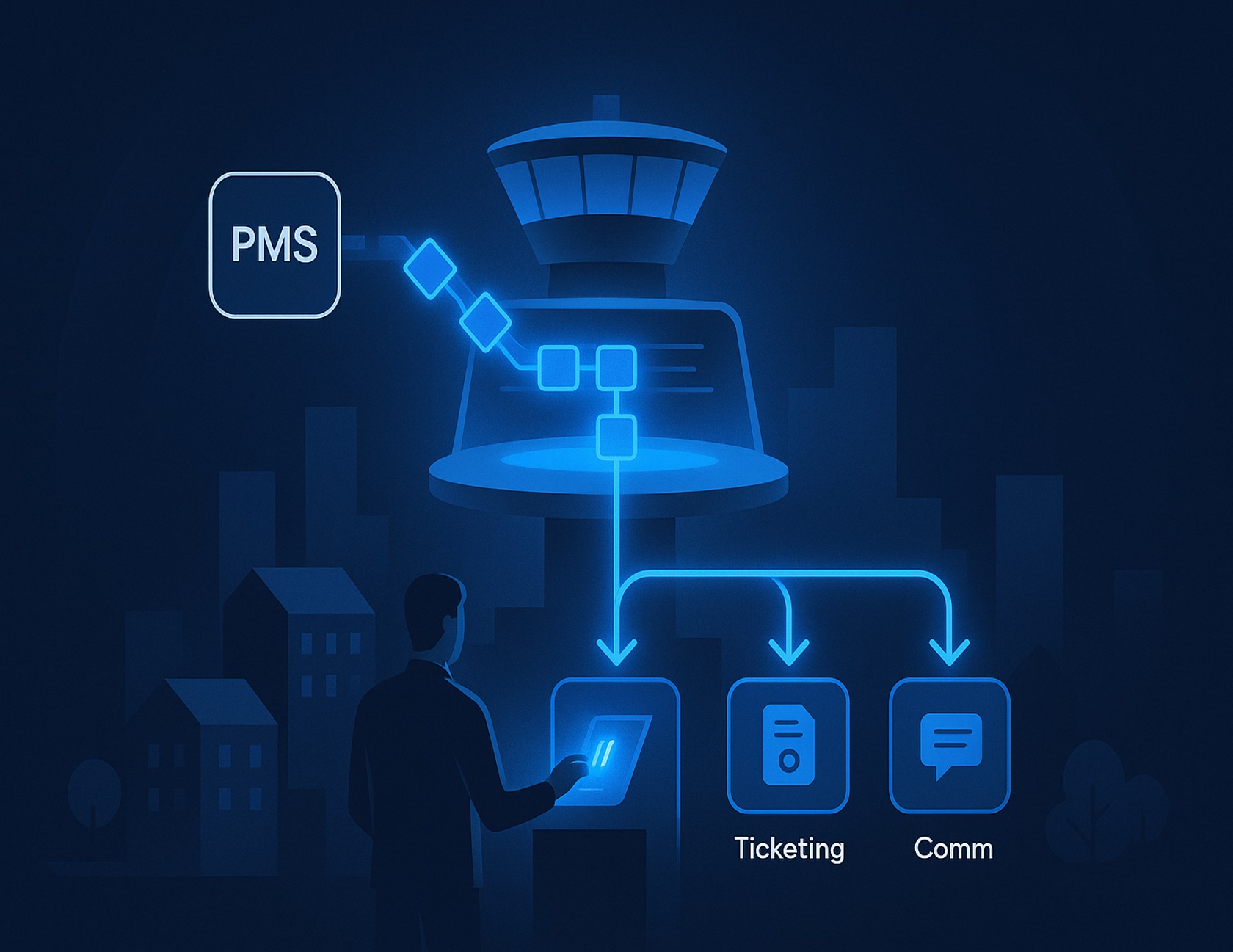
This scenario plays out across Class A multifamily operations because siloed touchpoints—even excellent ones—don't automatically coordinate. Service inconsistencies arise not from missing features but from operational latency, redundant actions, and unclear ownership between systems. A Unified Resident Experience Platform (also called a resident operations platform, resident workflow hub, or CX control tower) addresses this by functioning as a control tower: orchestrating events, establishing role clarity through standardized playbooks, and providing shared dashboards that make accountability visible across properties.
This article demonstrates how orchestration prevents the specific failure modes that compromise service consistency, the metrics that reveal coordination gaps before they become escalations, and a practical 90-day pilot framework to prove the model delivers the predictable excellence residents expect.
The Structural Cause of Service Lapses: Operational Latency and Redundant Actions
Most operations leaders assume service inconsistencies stem from capacity constraints—not enough staff, too many requests, or insufficient automation. The reality runs deeper. When resident workflows span multiple systems without orchestration, two structural problems emerge: operational latency and duplicate manual actions.
Operational latency is the accumulating difference between when an event actually happens and when each system records, relays, or acts on it. This creates cascading delays that erode service commitments even when individual systems perform correctly.
What operational latency looks like in PMS ↔ access ↔ ticketing
A resident signs their lease at 3:05 PM. The PMS records this immediately, but the access control system doesn't receive the sync until 3:21 PM—a 16-minute lag. Meanwhile, the welcome ticket auto-creates at 3:07 PM based on the PMS event, but the access system doesn't confirm permissions until 3:28 PM. Two welcome messages get sent because the ticket system and the communication platform each trigger independently. The resident's fob gets cut late. Most critically, the move-in service commitment clock starts before the necessary data exists across all systems to actually complete the workflow and deliver the seamless arrival experience that defines premium multifamily living.
This isn't a failure of any individual system. Each performed its function correctly within its own boundaries. The breakdown happened in the spaces between—the handoffs that required either real-time event synchronization or manual intervention. In well-run operations, these gaps get bridged through diligence and institutional knowledge. The problem scales poorly because operational latency compounds across properties. What works when a single property manager knows to manually check three systems before every move-in becomes unreliable when turnover reaches 20 units per week across multiple buildings.
Why manual handoffs magnify variance across properties
Manual handoffs create variance because they depend on individual judgment about when to act, which system holds the authoritative data, and who owns the next step. Property Manager A might check the PMS first thing each morning and immediately create corresponding tickets. Property Manager B might wait for residents to request service. Property Manager C might rely on weekly reports. All three approaches can work in isolation, but they produce wildly different service outcomes across a portfolio—undermining the consistent, high-touch experience that preserves resident satisfaction and property valuation.
The variance problem intensifies when responsibilities aren't clearly defined through a RACI framework (Responsible, Accountable, Consulted, Informed). If both the operations team and the IT team believe the other group owns access provisioning during move-in, residents experience delays while internal stakeholders point to different systems as the source of truth. When Finance needs to understand escalation costs but each property tracks issues differently, the organization lacks reliable data to improve processes and secure the operational excellence that distinguishes Class A properties.
Organizations often respond by adding more features—better reporting, additional automation, or new point solutions. Yet feature additions without coordination simply create more systems that must be manually synchronized, which increases the total surface area for operational latency rather than reducing it.
Top service consistency challenges:
- Operational latency between systems
- Redundant actions creating conflicting states
- Unclear handoff ownership and escalation paths
From silos to orchestration—how the control-tower model works
A Unified Resident Experience Platform functions as a control tower by managing the workflow layer above individual systems. Rather than replacing existing tools, the platform ensures events flow reliably between them while enforcing consistent processes across properties. Following ISO service management principles, three mechanisms make this orchestration effective: event-driven workflows with built-in reliability, standardized playbooks that define escalation paths, and shared dashboards that create cross-property accountability—all working together to deliver the hospitality-grade service residents expect.
Event-driven workflows (built-in reliability, retries, clear triggers)
Event-driven workflows replace batch processes and manual checks with immediate, automated responses to specific triggers. When a lease status changes to "executed" in the PMS, the platform immediately initiates a cascade: provision access credentials, create move-in inspection tickets, schedule resident onboarding communications, and update renewal forecasting dashboards. Each action happens through an API call to the appropriate system, and the platform tracks completion status for every step, ensuring the seamless service delivery that defines premium resident experiences.
The platform is architected to prioritize deep integration first—reliable connections with PMS and access control systems create the foundation—then orchestration coordinates the resulting events into a singular, reliable service fabric. Two technical properties make these workflows dependable. Built-in reliability ensures that if a network glitch causes the platform to send the same provisioning request twice, the access control system processes it only once through single-pass execution—residents don't receive duplicate credentials or conflicting permissions. Retry logic with exponential backoff means temporary failures don't become permanent gaps. If the ticketing system is briefly unavailable, the platform attempts delivery again after one minute, then five minutes, then fifteen, logging each attempt for visibility.
The platform also makes triggers explicit rather than implicit. Instead of assuming everyone knows that "lease executed" means "start move-in workflow," the trigger and its consequences become codified rules that apply consistently across all properties. New property managers don't need to learn 47 different scenarios through experience; the system enforces the playbook automatically while surfacing exceptions that need human judgment, ensuring consistent service delivery regardless of staff tenure.
Standard playbooks & escalation ladders (RACI at each stage)
Orchestration requires clarity about who is Responsible for executing each step, who is Accountable for the outcome, who must be Consulted before action, and who should be Informed afterward. A standardized playbook for move-in coordination might specify: Property Manager is Responsible for conducting the inspection, Operations Director is Accountable for service commitment adherence, Maintenance must be Consulted if prior work orders are still open, and Finance must be Informed of any deposit disputes.
This RACI clarity becomes especially valuable during service recovery. When a service commitment is challenged, the platform automatically initiates service recovery protocols according to preset rules, consistent with NIST incident handling guidelines. Here's how the escalation path works in practice:
Escalation Example:
Work order created → Maintenance Lead → 4 hours to first response → Property Manager escalation if T-60 minutes
A maintenance request that goes unacknowledged for two hours triggers a notification to the property manager. If still unresolved after four hours, it escalates to the regional director with full context: what was requested, when the service commitment was challenged, and what actions have been attempted. Nobody needs to remember escalation paths or manually track timing—the platform enforces the standard while logging every decision for later analysis.
Standardization doesn't eliminate judgment; it ensures judgment gets applied to genuine exceptions rather than routine coordination. When a property team decides to deviate from the playbook, that choice is visible and deliberate rather than happening invisibly through inconsistent execution that compromises service quality.
Shared dashboards that build cross-property accountability
Orchestration makes outcomes measurable in ways that siloed systems cannot. When each property tracks service commitments differently, comparing performance requires manual data aggregation that's usually weeks out of date. A shared dashboard pulling from the orchestration platform shows real-time service adherence across all properties, broken down by workflow type, property, and team member—providing the transparency needed to maintain the consistent excellence that defines Class A operations.
This visibility creates accountability through transparency rather than surveillance. Operations directors can identify which properties consistently meet service commitments and which struggle, then investigate whether the problem stems from staffing, process adherence, or external factors like contractor reliability. Property managers can see their performance relative to peers and access specific workflow logs to understand where operational latency occurred. Finance teams can track the cost of escalations and identify which failure modes generate the most resident complaints, protecting property valuation through proactive service improvement.
The platform also enables proactive intervention. If three properties show declining first-response times on work orders over the past two weeks, leadership can address the trend before it becomes widespread service inconsistency. Without orchestration, this pattern would only become visible after consolidating monthly reports—too late for meaningful correction and too late to prevent resident dissatisfaction.
Competitive Reality Checks:
Premium Features Do Not Guarantee Coordinated Outcomes
High feature velocity across point solutions can paradoxically increase operational latency. Without orchestration, more features create more handoffs requiring synchronization, ultimately compromising rather than enhancing service consistency.
Monolithic Suites Still Experience Coordination Gaps
Single-vendor breadth doesn't guarantee event reliability. Even integrated suites need orchestration to prevent coordination gaps and clarify handoffs between modules, ensuring the seamless service flow that residents expect.
Integration-First Is Necessary, Not Sufficient
Solid API plumbing provides the foundation, but deferring the workflow layer means coordination impact remains unrealized. Integration plus orchestration beats either approach in isolation for delivering hospitality-grade service.
What to measure to stop SLA leaks (starter KPIs)

Orchestration creates reliable data about workflow performance, but effective measurement requires focusing on leading indicators that predict service lapses before they cascade into escalations. Drawing from established operations management practices, organizations should track three categories of metrics during a pilot: time-based service commitments, coordination health, and cadence discipline.
First-response time, resolution commitments, escalations/100 units
First-response time measures the interval between when a workflow initiates and when the responsible party takes their first action. For move-ins, this might be the time between lease execution and access credential provisioning. For maintenance requests, it's the delay between ticket creation and technician acknowledgment. Track both the median (p50) and the service floor metric (p90)—the 90th percentile reveals the longest delays experienced, ensuring even exceptions adhere to high standards for premium resident engagement. First-response time predicts ultimate service performance because delays early in a workflow compound as they move through subsequent steps.
Resolution commitments track whether workflows complete within the defined window. A move-in workflow might have a 24-hour resolution commitment, meaning all steps—credential provisioning, inspection completion, and resident notification—must finish within one day of lease execution. This metric directly measures the outcome residents experience and forms the basis for the consistent, hospitality-grade service that defines Class A properties.
Escalations per 100 units normalizes escalation frequency to portfolio size, making performance comparable across properties of different scales. A property with 200 units that generates five escalations per month performs equivalently to a 400-unit property with ten escalations. This metric reveals whether escalations stem from operational issues or normal variance in a large portfolio.
Operational latency detection & redundant-action prevention
Operational latency detection measures the gap between when an event should trigger a downstream action and when that action actually occurs. If access credentials should provision within ten minutes of lease execution but actually average 45 minutes, the platform logs this as operational latency. Tracking these coordination gaps separately from service commitment breaches enables teams to address coordination problems before they cause resident-facing service lapses.
Redundant-action prevention counts how often the platform prevents duplicate work through built-in reliability checks. When the PMS and the ticketing system both try to create the same move-in inspection, the platform recognizes the duplication and consolidates them into a single ticket. High redundant-action counts indicate integration reliability issues—systems aren't staying synchronized, forcing multiple attempts to complete the same task. Low counts after implementing orchestration demonstrate that workflows now flow cleanly without manual deduplication, delivering the seamless coordination residents expect.
Weekly metric cadence to correct coordination gaps early
Monthly reporting works for strategic planning but fails for operational correction. By the time monthly reports reveal a problem, hundreds of resident interactions have already been affected, potentially compromising satisfaction and retention. Weekly metric reviews create the cadence needed for rapid correction. Operations teams should review first-response time, resolution commitment adherence, and escalation trends every week, investigating any property that shows degradation from its baseline.
For example, a weekly review might flag that move-in access is trending toward commitment breaches at two properties. The dashboard shows a spike in "Lease → Active" events without matching "Access → Provisioned" confirmations within ten minutes. The team tightens the retry policy and clarifies who owns rechecks at the 15-minute mark before the coordination gap becomes systematic service inconsistency.
This cadence also supports continuous improvement. When a team experiments with a new playbook or adjusts RACI assignments, weekly metrics reveal whether the change improved performance or introduced new coordination gaps. The short feedback loop enables evidence-based refinement rather than waiting months to discover an experiment compromised service quality.
Zero-click matrix—service consistency challenges → orchestration solutions
Most service lapses follow predictable patterns. Rather than treating each incident as unique, operations leaders can map common failure modes to specific orchestration solutions. The matrix below provides a starting framework for addressing the four most frequent coordination breakdowns in Class A multifamily operations.
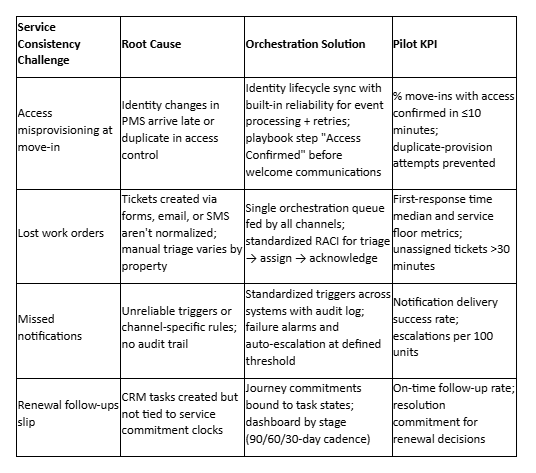
Access misprovisioning at move-in → identity lifecycle sync
Access credential problems at move-in represent one of the most visible service lapses because residents experience them immediately—they cannot enter their unit, access amenities, or use parking. This directly compromises the seamless arrival experience that defines premium multifamily living. The root cause typically involves either manual data entry from the PMS to the access control system or batch synchronization that runs on a schedule rather than responding to events.
Identity lifecycle sync means the platform monitors lease status changes in real-time and immediately provisions access credentials when a lease reaches "executed" status, following NIST digital identity guidelines. The platform maps resident information from the PMS to the access control system's data model, applies role-based permissions (residents get different access than maintenance staff or vendors), and triggers credential creation through the access control API. If the provisioning fails, the platform retries automatically and escalates to the property manager if the issue persists beyond the defined threshold.
Measuring success requires tracking first-response time (how quickly credentials provision after lease execution—target: under ten minutes) and error rate (how often manual intervention is needed). A well-orchestrated move-in should provision credentials reliably within this window with zero manual corrections needed, delivering the frictionless experience residents expect from Class A properties.
Lost work orders → single orchestration queue + RACI
Work orders get lost when residents submit requests through multiple channels—a resident portal, email to property staff, phone calls, or in-person conversations—and no system consolidates them into a single queue. Even when requests enter a ticketing system, unclear ownership means they sit unacknowledged while different team members assume someone else is handling them, compromising the responsive service that distinguishes luxury properties.
A single orchestration queue means all service requests, regardless of submission channel, flow into the platform where they're normalized, deduplicated, and assigned to the responsible party based on RACI rules. The platform examines request type, property location, and current workload to route each ticket appropriately. Maintenance requests go to the maintenance team, amenity reservations route to the concierge system, and lease questions reach the leasing office.
RACI enforcement makes ownership explicit. The platform automatically assigns a Responsible party when creating the ticket, notifies them immediately, and starts the service commitment clock. If the responsible party doesn't acknowledge the request within the defined window—typically four hours for maintenance issues—the platform escalates to the Accountable stakeholder with full context. This eliminates the "I thought you were handling it" failure mode by making every assignment visible and tracked, ensuring the reliable service response residents expect.
The pilot KPI focuses on acknowledgment time rather than resolution time because acknowledgment predicts ultimate success. Teams that consistently acknowledge work orders within two hours almost always meet resolution commitments; teams with acknowledgment delays rarely recover. Track both median and service floor (p90) first-response times, and flag any tickets remaining unassigned for more than 30 minutes.
Missed notifications → standardized triggers + audit logs
Residents miss important notifications when communication timing varies by property or when notifications are sent manually by team members who may forget or be unavailable. Common examples include move-in confirmations, amenity booking reminders, maintenance completion notices, and lease renewal prompts. These communication gaps erode the attentive, hospitality-grade experience residents expect.
Standardized triggers mean the platform defines exactly when each notification type should send. Lease execution triggers a move-in confirmation within five minutes. Amenity bookings trigger a reminder 24 hours before the reservation. Maintenance ticket closure triggers a completion survey within one hour. These triggers apply uniformly across all properties, eliminating variance from individual habits or workload and ensuring consistent communication that reinforces premium service.
Audit logs provide visibility into whether notifications actually delivered. The platform records every attempt to send a notification, the delivery status returned by the communication system, and any failures that require retry or escalation. Operations teams can search the audit log to definitively answer "did this resident receive the notification?" rather than relying on memory or searching multiple email systems.
The pilot KPI requires tracking notification delivery success rate and monitoring escalations per 100 units. An aggressive target demonstrates orchestration reliability: if the platform cannot consistently deliver notifications with full audit visibility, it's not yet ready to replace manual processes and deliver the communication consistency residents expect.
Renewal follow-ups slip → journey commitments with task binding
Renewal workflows often falter because CRM tasks get created but exist independently of service commitment clocks. Marketing creates a "60-day renewal outreach" task, but no system tracks whether it actually completes on time or escalates if missed. This creates invisible gaps where renewal opportunities slip through without accountability, potentially compromising resident retention and property revenue.
Journey commitments bind task states directly to time-based service standards. The platform creates renewal tasks at 90, 60, and 30 days before lease expiration, each with its own commitment clock. If the 90-day outreach doesn't complete within three business days, the system escalates to the leasing director. The dashboard shows renewal pipeline status by stage, making it immediately visible which residents are approaching decision points without completed follow-ups.
Track on-time follow-up rate (percentage of renewal tasks completed within commitment windows) and resolution commitment for renewal decisions (time from first outreach to signed renewal or notice to vacate). This transforms renewals from a passive process hoping residents respond into an orchestrated workflow with clear ownership and escalation—securing the retention rates that protect property valuation.
How to pilot this in 90 days (summary playbook)
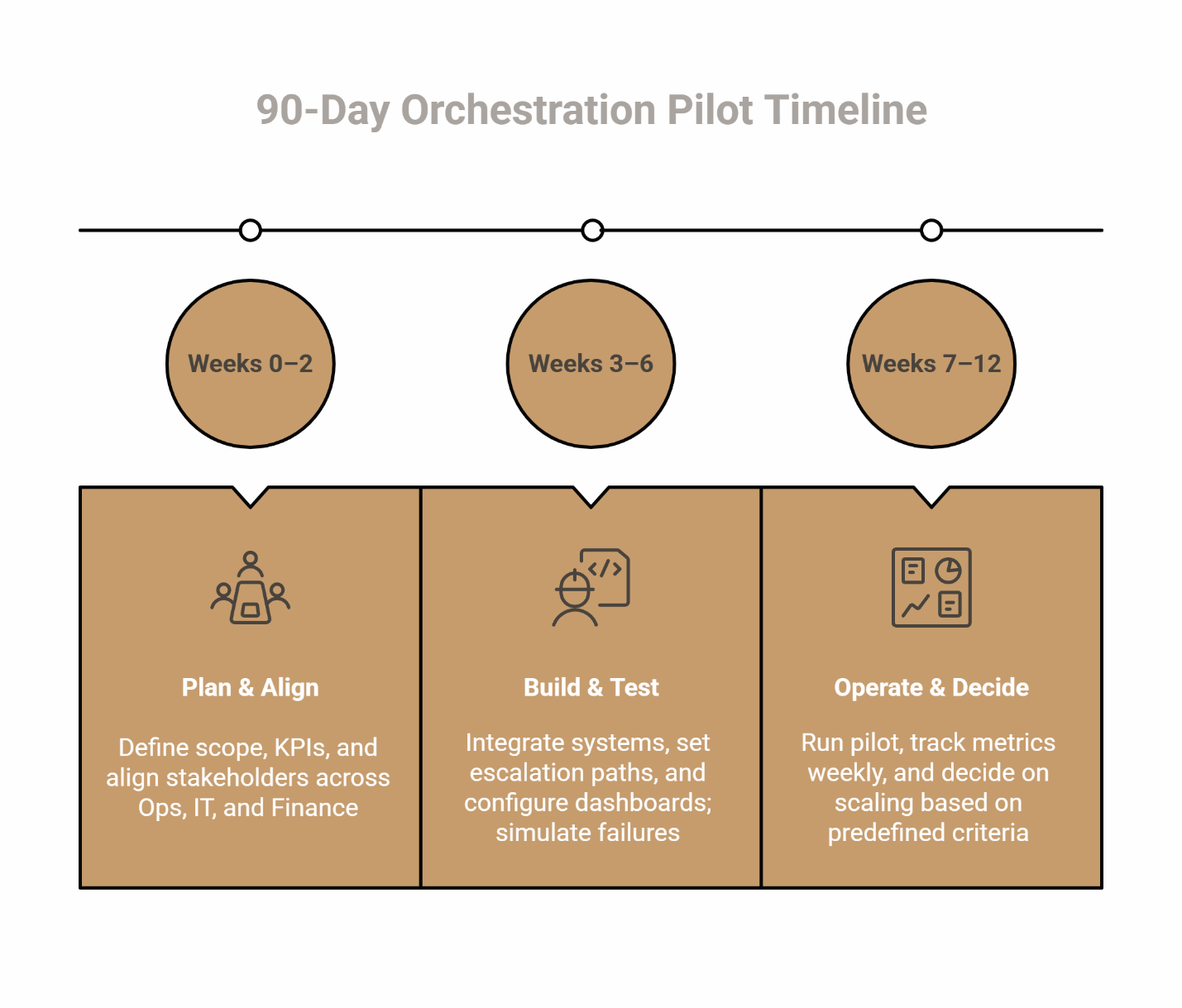
Implementing orchestration across an entire portfolio simultaneously creates excessive risk and makes root cause analysis difficult when problems emerge. A structured 90-day pilot at one or two properties generates the evidence needed to scale confidently while protecting the consistent service quality residents expect. "Pilots measure confidence, not perfection."
Weeks 0–2: Define scope & KPIs; align Ops/IT/Finance; pick 1–2 properties
The pilot should focus on two to three resident workflows end-to-end rather than attempting partial orchestration across multiple workflows. Move-in coordination works well as an initial scope because it's bounded (clear start and end points), high-visibility (residents notice coordination failures immediately), and cross-functional (involves PMS, access control, ticketing, and communications). Consider adding work order triage and renewal follow-ups as complementary workflows that demonstrate orchestration's impact on the complete resident journey.
Define success metrics before starting. Typical pilot KPIs include: first-response time for credential provisioning (target: under ten minutes), move-in resolution commitment adherence (target: 95% complete within 24 hours), escalations per move-in (target: less than 0.05, meaning one escalation per 20 move-ins), and redundant-action prevention rate. These metrics must be measurable with current systems to establish a baseline before orchestration begins, providing clear evidence of service improvement.
Stakeholder alignment prevents mid-pilot conflicts about scope or authority. Operations owns the workflow design and service commitment standards. IT owns integration reliability and security review—confirm that the prerequisite PMS and access control integrations are already reliable and producing timestamped events. Finance needs visibility into pilot costs and projected ROI if successful, particularly how improved service consistency protects resident retention and property valuation. All three groups should review and approve the pilot plan before implementation starts, with explicit agreement about decision rights when tradeoffs emerge.
Property selection should balance opportunity and demonstration value. Choose one property with stable operations (lower baseline service inconsistency rate) to demonstrate orchestration's benefits even in well-run environments, and one property with coordination challenges (higher inconsistency rate) to prove the model addresses real operational problems. Avoid properties currently undergoing major transitions like renovations or management changes that could confound pilot results.
Weeks 3–6: Instrument events & dashboards; set escalation paths
Instrumentation means configuring the platform to monitor specific events in each system and to apply reliability mechanisms and retry logic. For move-in orchestration, this requires integrating with the PMS to detect lease executions, connecting to the access control system to monitor provisioning status, linking to the ticketing system to track inspection creation, and hooking into the communications platform to log resident notifications. Each integration should include health monitoring so operations teams receive alerts if a system becomes unavailable, protecting service continuity.
Publish RACI assignments and escalation ladders inside each playbook before going live. Define precisely who is Responsible for executing each step, who is Accountable for service commitment adherence, who must be Consulted before action, and who should be Informed of outcomes. Make escalation timing explicit: after how many minutes does an unacknowledged work order escalate? Who receives the escalation notice? What context do they need to make decisions and maintain service recovery?
Dashboard configuration should make pilot KPIs visible in real-time. The operations team needs a view showing all active workflows, their current step, time remaining until commitment breach, and any blocked steps requiring attention. The regional director needs a summary view comparing pilot properties to the rest of the portfolio on the defined success metrics, revealing opportunities to replicate excellence. IT needs a technical health dashboard showing integration uptime, API response times, and error rates.
Test escalation paths during the setup period by simulating failures to confirm notifications reach the right people with sufficient context to make decisions. Don't wait for the first real incident to discover escalations aren't working and compromise resident service.
Weeks 7–12: Run & decide with weekly metric cadence
Hold a weekly operations review focused exclusively on pilot metrics. Examine first-response time trends (median and service floor), resolution commitment adherence rates, escalations per 100 units, operational latency detection patterns, and redundant-action prevention counts. Investigate any property showing degradation from baseline and correct coordination gaps before they become systematic service inconsistency that affects resident satisfaction.
Capture detailed incident data during escalations. When workflows breach service commitments, log the root cause, the point of failure, and whether the issue stemmed from operational latency, unclear RACI, or external factors. This incident analysis informs continuous refinement of playbooks and escalation rules throughout the pilot period, ensuring the platform evolves to deliver increasingly reliable service.
Define clear scaling criteria to ensure momentum and eliminate post-pilot deliberation. For example: "If the pilot achieves 90% first-response time under ten minutes and 95% move-in resolution within 24 hours over a consecutive 30-day period, with no more than 0.05 escalations per move-in, we will immediately begin scaling to the next five properties." This specificity eliminates ambiguity about what constitutes success and prevents endless post-pilot debate that delays service improvement across the portfolio.
The criteria should also define what happens if the pilot doesn't meet targets. Will the team iterate on workflow design and run a second 90-day pilot? Will they reduce scope to a simpler workflow before attempting move-in again? Will they pause to address foundational integration issues? Making these decisions before the pilot prevents paralysis when results fall short of aspirations but still demonstrate meaningful improvement in service consistency.
Finally, assign responsibility for the scale decision. One executive should have clear authority to approve or decline based on whether criteria were met, without requiring consensus from a large committee. This accelerates the decision cycle and prevents endless deliberation that wastes the pilot investment and delays the portfolio-wide service improvements residents deserve.
Coordination beats feature sprawl
Service inconsistencies arise when well-intentioned systems don't coordinate effectively. Adding more features rarely solves this problem because each new capability creates additional handoffs that require synchronization. Orchestration addresses the root cause by managing workflow coordination above the feature layer, ensuring events flow reliably between systems while enforcing consistent processes through standardized playbooks and shared visibility—all working together to deliver the hospitality-grade service that defines Class A multifamily operations and protects property valuation through resident satisfaction.
The practical path forward starts with a focused pilot that proves orchestration prevents specific service consistency challenges at one or two properties. Success in this bounded scope generates the confidence and evidence needed to scale across a portfolio, gradually orchestrating additional workflows until most resident interactions benefit from reliable coordination and seamless service delivery.
Organizations that prioritize orchestration over feature accumulation build operational systems that scale reliably, reduce escalations through proactive coordination, and provide residents with the consistent, premium experience that defines Class A multifamily operations. The alternative—continuing to add features while hoping manual coordination fills the gaps—creates growing operational complexity with diminishing returns, ultimately compromising the service predictability that drives resident retention and sustains property value.
For operations leaders ready to move beyond feature sprawl, the path begins with understanding current service consistency challenges, mapping them to orchestration solutions, and launching a disciplined pilot that measures whether coordination actually improves outcomes. The evidence will speak clearly.
References
[1] ISO/IEC 20000-1 — Service management system principles: https://www.iso.org/standard/70636.html
[2] NIST SP 800-63 — Digital Identity Guidelines: https://pages.nist.gov/pages-root/
[3] NIST SP 800-61r2 — Computer Security Incident Handling Guide: https://csrc.nist.gov/pubs/sp/800/61/r2/final
[4] Harvard Business Review — Operations Strategy: https://hbr.org/topic/subject/operations-strategy
Author: The ElevateOS Insights Team
About the Author: The ElevateOS Insights Team is our dedicated engine for synthesizing complex topics into clear, helpful guides. While our content is thoroughly reviewed for clarity and accuracy, it is for informational purposes and should not replace professional advice.
Our Editorial Process: We prioritize clarity, source transparency, and practical guidance. Articles are reviewed for accuracy and updated when strategy or standards evolve.